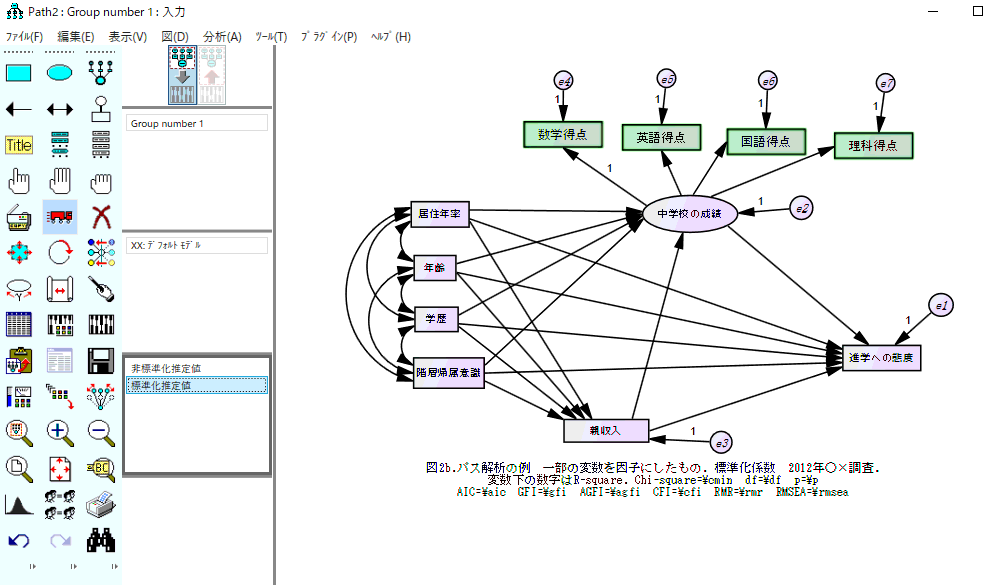
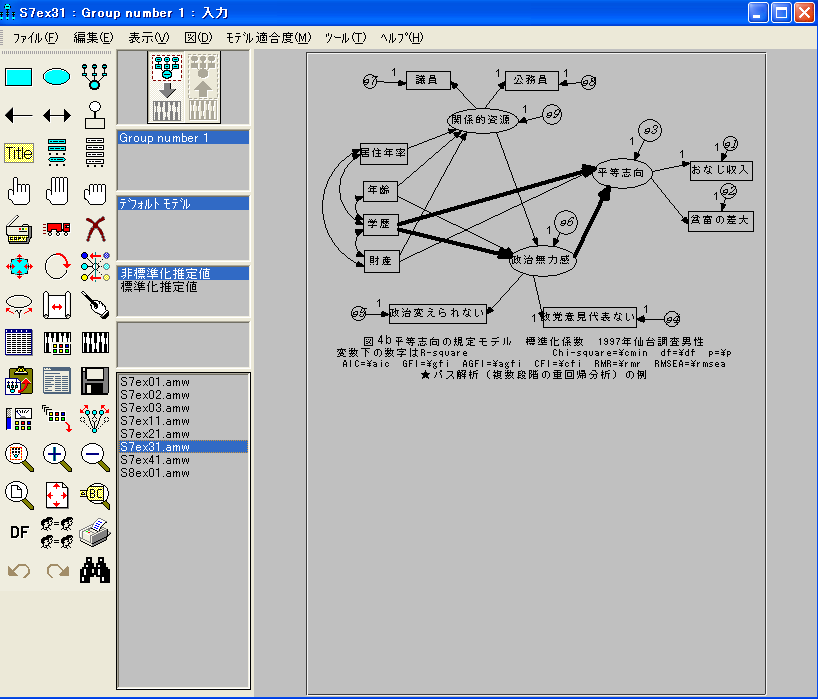
社会調査データに関して構造方程式モデルで分析する場合は、下記の図のようなモデルで考えると良いだろう。左端に年齢や教育年数などの基本属性を配置し、次に、関係的資源や、財産保有数、階層帰属意識など社会的地位に関するものを置く。右端に、最終的な被説明変数として、自分の研究テーマに関するもの(この例では将来不安感の質問項目)を置くとよい。社会的地位の次に、このモデルの被害金額の代わりに、基本的な態度変数を置いてもよい。社会的地位や、態度変数がないモデルは、決定係数が低くなりがちであるが、調査データの中に、適切な変数がない場合は、仕方がないことである。
4.分析時の注意点
4.1.データ中に欠損値がある場合
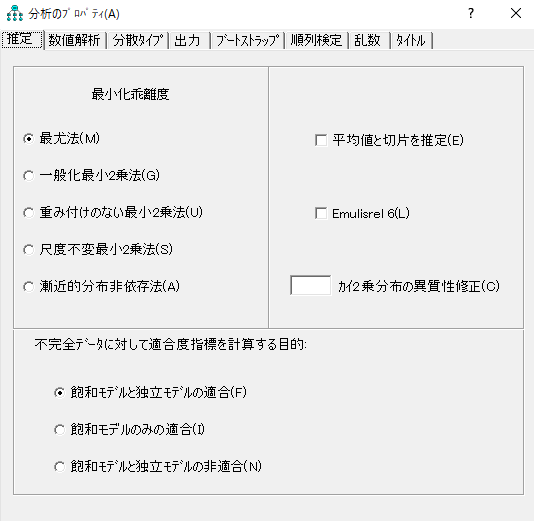
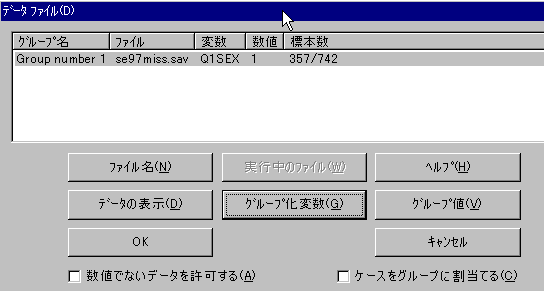
SPSSデータファイル中に欠損値がある場合は、AMOSでは一部の分析結果が出ない。ただしAMOSの画面上の「表示」をクリックして「分析のプロパティ」を選び、推定タブの中の「平均値と切片を推定」を選べば、分析結果が出る。
しかしこの場合、GFIやAGFIや標準化係数などが出ない。上記のように、SPSS本体を使って、欠損値を除いたデータファイルをあらかじめ作っておいた方がよい。
4.2.エラーとなり分析結果が出ない原因
1)自分で書いた観測変数名が間違っている。データファイルの中に存在する名前を書くこと。
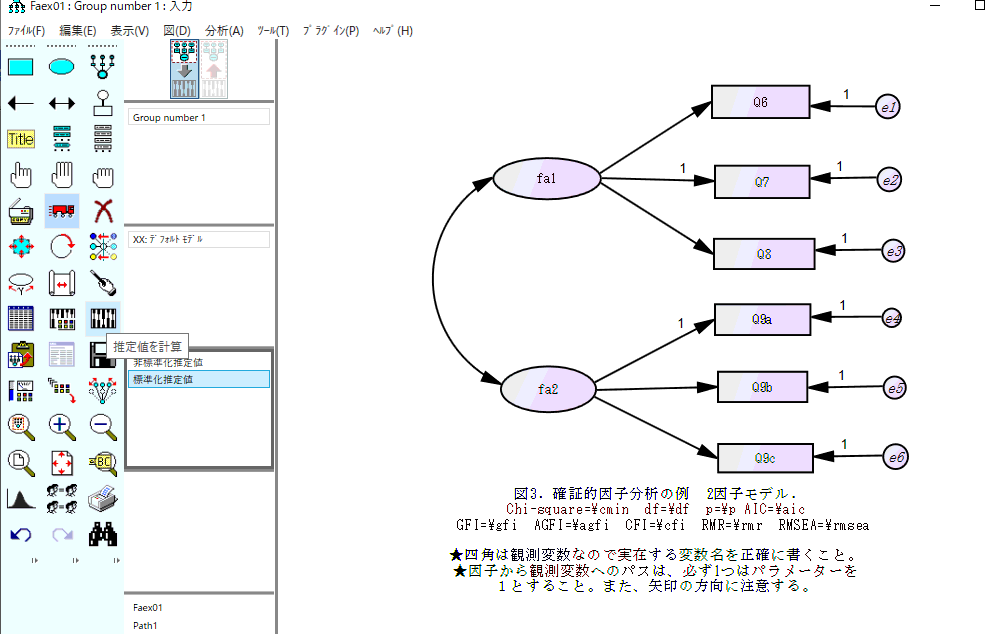
2)因子を作る時に、上記の固定母数(パラメーター1)を忘れた
固定母数についての説明をよく読むこと。因子から観測変数へのパスを1つだけ右クリックしてプロパティ → パラメーターボックスに半角数字で1を入れる。
3)誤差項をつけ忘れた −矢印がささっている変数(内生変数)には必ず誤差項をつけること
上の図で、両方向矢印ボタンの右にあるボタン(誤差項をつけるボタン)を使えば、誤差項をつけることができる。
誤差項には、e2 など適当な名前をつける。他の変数と同じ名前でなければよい。
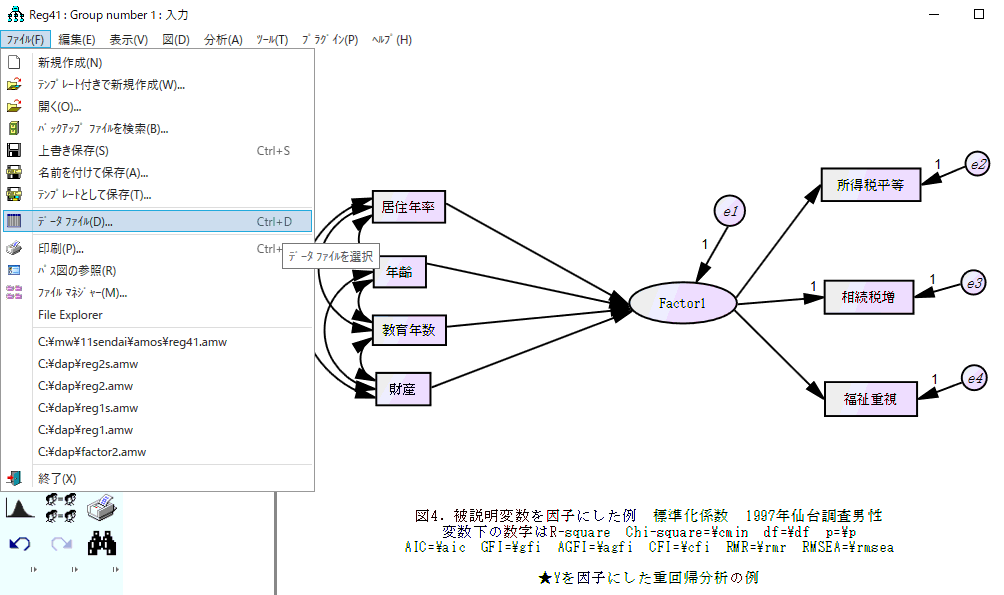
分析した時にエラーが出る理由は、おおむねこの3つの理由である。その他、あまり似ていない複数の観測変数を使って無理な因子を作ったり、強い多重共線性がどこかにあるモデルなど、不適切なモデルは分析結果が出ない。いくつの因子をどのように作るべきか等を、よく考えてモデルを作れば良い。試行錯誤が大切。テキスト出力の内容を見ると、問題のある変数が表示されるので、モデル内のどこが不適切か見当をつけるとよい。なお社会調査データを用いる場合、外生変数として年齢や学歴、収入(または財産)など基礎項目を入れた方が、モデルの適合度は上がる。
また、誤差間相関をやたらと入れたモデルは不自然すぎて良くない。
4.3.カテゴリー変数について
連続量の変数のみをAMOSで扱うことができる。4段階回答などの変数ならば、連続量として扱ってもよい。しかし2段階では、連続量としてみなすことはできないとされる。また、例えば、職業の問で、事務職1,専門職2,その他3などとしたものは、数字に量的な意味はない「名義尺度」あるいは「離散変数」である。このようなカテゴリー変数を、AMOSの分析にて使ってはいけない。
しかしダミー変数(0,1型の変数)ならば、分析に用いてもよい。SPSS本体を使って、ダミー変数をあらかじめ作っておけばよい。
ダミー変数作成のSPSSシンタックスの例
SPSSのシンタックスウィンドウにて、以下を実行する
以下は、dsenという新たなダミー変数を作る例である。dsenの値は、0,1である。
もともと存在する変数Q5をもとに、Q5が1と4の場合のみ、dsenの中身を1にする。
それ以外はdsenは0となるという例。1行目で、新変数dsenを作成している。
compute dsen=0.
if (Q5 =1 ) dsen=1.
if (Q5 =4 ) dsen=1.
5.操作法を把握するこつ
基本的に、AMOSフォルダに入っているサンプルプログラムをいろいろ読み込んでみて、そのパス図を書き換えて分析してみると分かりやすい。サンプルプログラムをもとに、変数名だけを書き換えて、何度か分析してみることが、AMOSの使い方を覚えるこつ。
また、自分が作ったモデルが動かない時は、上記3.2をよく読み、エラーが出る原因を理解することが重要。
ソフトの欠点は以下です。最低限、これらは早急に改善してほしいところです。
・図の矢印上に、数字をのせることができるようにする。係数が自由に動かない。
・SPSSデータを読み込んだ場合、欠損値処理を、平均値で置き換え以外にもできるようにする。
・2値変数(1−0型の変数)を扱えるようにする。現状ではリズレルやEQSを買うしかない(矢印がささっていない変数として2値変数を使うのは問題ない)。現実には、データ人数が約1000人以上いれば、2値変数を使っても、あまり問題ないようである。厳密には、モデルのあてはまりが悪くなる。また、以下を参考にすれば、AMOSでもある程度は2値変数を扱えるかもしれない
・有意水準を図上で表示可能にする。
6.AMOSによるカテゴリカルデータの分析
以下のAmos User Guideにて"dichotomous"で検索する。
Amosユーザーズガイド 英語版PDFファイル
あるいは以下を参考にする。
researchgate Q & A
AMOSによる2値データの分析について
IBM support Q & A
Amosユーザーズガイド 日本語版PDFファイル
Talkstats Q & A
AMOSでのカテゴリカル変数の扱いについては、AMOSのHELPで
Help->Contents in AMOS, Index tabを選択し, "Parameter identification with dichotomous variables" で検索する。
順序カテゴリカルrescaling は、AMOSにおいてベイジアン推定(Bayesian Estimation)によってのみ可能。最尤推定法のための分布の前提が当てはまらないデータの場合は、Bootstrappingを用いる。
順序カテゴリカルデータの扱いについて
Amosdevelopment Q & A
Amosユーザーズガイド 日本語版PDFファイル 例33 順序カテゴリカルデータ
SEM with Amos PDFファイル
SEM with Amos2 PDFファイル
参考文献
朝野煕彦・小島隆矢・鈴木督久. 2005. 『入門 共分散構造分析の実際』講談社.
狩野裕・三浦麻子.2002.『グラフィカル多変量解析―AMOS、EQS、CALISによる目で見る共分散構造分析』現代数学社.
村瀬洋一・高田洋・廣瀬毅士. 2007. 『SPSSによる多変量解析』オーム社.
豊田秀樹. 2007. 『共分散構造分析 Amos編―構造方程式モデリング』東京図書.
与謝野有紀他編.2006.『社会の見方、測り方 −計量社会学への招待』勁草書房.
SmallWaters Corporation. 1997. Amos Users' Guide Version 3.6. SPSS.
Byrne, Barbara. 2009. Structural Equation Modeling With AMOS: Basic Concepts, Applications, and Programming (Multivariate Applications) 2 edition. Psychology Press.
LISREL8 評価記事と簡単マニュアル
SPSS社では、リズレルのバージョン8に対応する予定はないが、リズレル8をどこかの会社を通して買うことはできる。リズレルには、ダミー変数への対応など、エイモスにない機能もあり、便利なこともある。ただしエイモスのように、図を書いてボタンを押すと分析してくれるわけではない。自分でプログラムを書く必要があるが、以下のように、プログラム作成を補助する機能があり、さほど難しくはない。
SPSS形式データを読み込んでリズレルを使う方法
LISRELを使うには、素データの読み込みや、共分散行列の読み込みなど、データ読み込み法が何種類かあるが、SPSS形式データを読み込むのが、もっとも簡単であろう。その場合、リズレルのプログラム文(SIMPLISやLISREL)を書く前に、SPSS形式データを読み込み、プレリス形式データ(Prelis system file)を、まず作ることになる。以下の手順で操作する。
1)プレリス形式データの作成
画面上Fileをクリック → New Prelis Dataを選び OKボタンを押す
画面上Fileをクリック Import External Data
Fileの種類ボックス→ SPSS for Windows
何もチェックせずにDoneボタン
名前をつけて保存する .psfとつくファイル名で保存
これで、プレリス形式データが保存される。
2)Simplisプログラム作成準備
画面上Fileをクリック → New Simplis Project
projectとは命令文やデータやパス図などを1つにしたファイルである。
名前をつけて保存する .spjとつくファイル名で保存
これで、プログラム(これから書く)が保存される。
なお、.outが出力ファイル、 .pth がパス図のファイルである。
spjファイルの中に、これらがすべて入っている
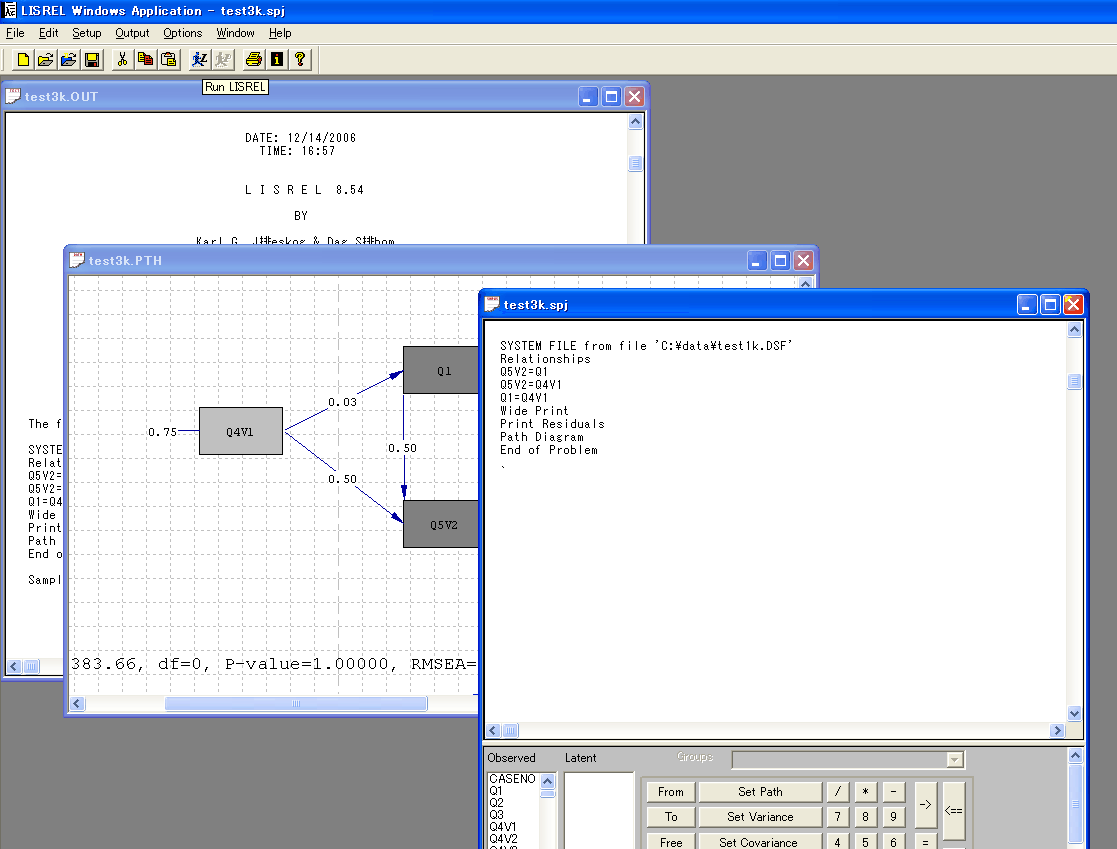
3)画面上Setupをクリック → Variablesを選ぶ
Add/Read Variablesボタン
Read from fileのボックスをクリックし、
ファイルの種類はPrelis system fileを選択
Browsボタンを押し、 .psfとつくファイルを読み込む
データウィンドウが表示された状態で、画面上Dataをクリックし、Define Variablesを選択すると、欠損値指定等ができる
4)画面上Setupをクリック → Build SYMPLIS Syntaxを選択
以下のような命令文が自動的に生成される
SYMPLISというのが分かりやすい形式のプログラム文である。
LISREL形式の文だと、Path DiagramをPD と書くなど省略されておりやや分かりにくい。
★SYMPLIS文の例
SYSTEM FILE from file 'C:\data\test1k.DSF'
Relationships
Q5V2=Q1
Q5V2=Q4V1
Q1=Q4V1
Wide Print
Print Residuals
Path Diagram
End of Problem
5)分析モデルを数式の形式で書く
プログラム内の、Relationshipsの後に変数名と数式を書く。
以下の例のように書けばよい。イコールの左側が被説明変数Y
Q3などはSPSSファイル内の変数名を書く
以下の例では、Q3をYとして、 Q1 Q4がXとしている。さらにQ1もYとなる、
2段階の重回帰モデル(パス解析モデル)となっている。
Q3=Q1
Q3=Q4
Q1=Q4
Path Diagram の上に
Wide Print
Print Residuals
などの命令文を書いても良い。残差などが出力される。
6)モデルにもとづき計算実行
人が歩いているボタン(Lがついている)を押すと計算が始まる。上記の図を参照。
7)計算結果が出る
パス図が表示された状態で、画面上の方のEstimates ボタンを押し、
Standaridized Solution 等を選ぶと、標準化解などが表示される。
Expected Change を選ぶと、入れるべきパスなども表示される
計算結果のファイルを適当な名前を付けて保存する
以下は古い文章
SPSS LISREL7.2 評価記事と簡単マニュアル
共分散構造分析(共分散分析とはまったく別のもの)は近年様々な分野で使われており、その分析プログラムとしては、SPSSのリズレル7が有名なものの1つである。白倉(1991)が日本語による数少ない解説書だが、これは文章が日本語として未整理で、残念ながら、これを読んでもプログラムの組み方が分からないことは、私の周囲では定評がある。
この文章をよくよく読むと、SPSSのデータからリズレルで分析したい変数を取り出すには、namesというコマンド(NAライン)を使う、ということが分かる。しかし、現在のWindows用SPSSリズレルの最新版バージョン7.2には、namesコマンドがない。だから、この文章を読んでも、リズレル7.2は使えない。ただし、この文章を読めば、リズレルモデルの数学的な特徴は把握できるかもしれない。以上の事情から、Windows用SPSSリズレル7.2の簡単なマニュアルを作成した。
リズレルのバージョン7.2では、namesコマンドの代わりにprelisコマンドを使う(他にもいろいろと方法はあるらしい)。これを使うと、たとえば、社会調査データの何十問もある質問項目のうち、10項目ほどについて、リズレルで分析したい場合、その10項目だけを取り出してリズレルで読み込むことができる。
以下が、プログラムの文例である。SPSSのデータ読み込み文の後にこれを書けば、リズレルモデルを用いた分析ができる。ここでは、プログラムの1例として、ある調査票の質問項目中の一部の問を用いたプログラムを提示する。分析に用いる質問項目すべてをprelisコマンドの文中に書けばよい。
共分散構造分析について基本的なことをある程度理解していれば、以下のプログラム文例と図を比較し、変数名を変えて同じ様なプログラムを書くことによって、SPSSリズレルを用いた分析ができるだろう。
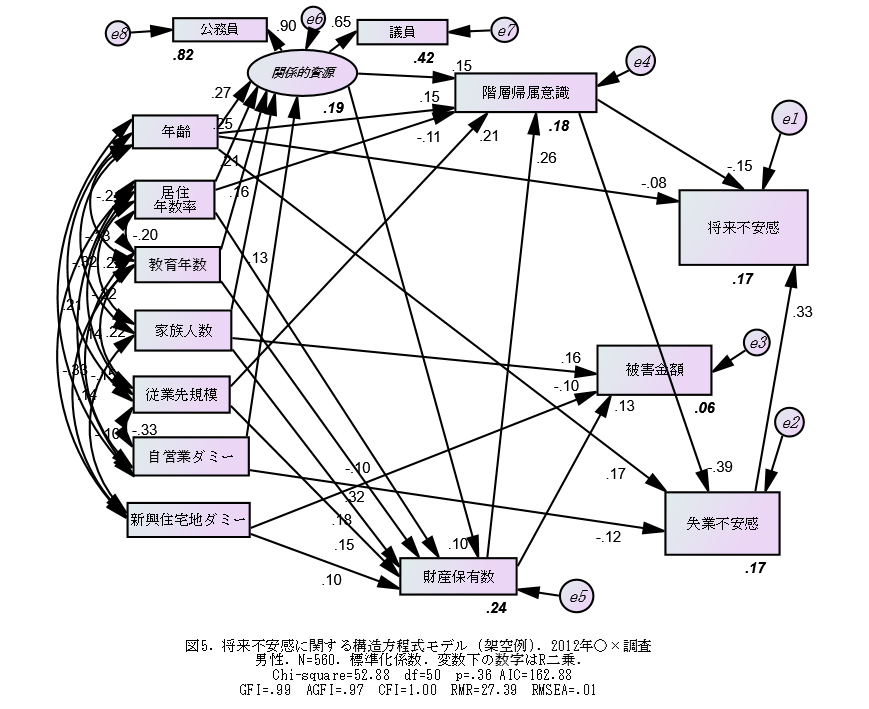
このプログラム例は、下記の図3のようなモデルを表している。図中の楕円で表されている変数が潜在変数(因子)である。どのような観測変数(現実に存在する変数)を用いて潜在変数を作ったか(測定モデル)は、図1と図2を見れば分かるだろう。
図3では、最終的に説明される潜在変数が2つ(大衆的文化活動、正統的文化活動)あり、それら2つの被説明変数を説明するために、説明変数が4つ存在する、という因果関係のモデルを表している。
プログラムの最後の解説★★★を印字して、プログラムの文例と照らし合わせてみれば、プログラムのおおまかな構造は理解できるだろう。より詳しくは、リズレルのマニュアル(英語版しかないが)の、パス図とプログラム例を見れば分かる。英語は難しくとも、図を見ながらプログラム例を真似して、変数名だけを変えてプログラムを書いてみれば、結構分析できる。SPSSのヘルプにも日本語によるごく簡単な解説がある。
注 現在、諸般の事情で、図が作成中で存在しません。しばしお待ちください。
参考文献
白倉幸男.1991.「LISREL: リズレルモデル」.三宅一郎他編.『新版SPSS
X 3 解析編2』223-310.東洋経済新報社.
Joreskog&Sorbom. 1989. 『 LISREL7 :A Guide to Program and Applications.
2nd edition 』 SPSS
SPSS. 1990. 『SPSS LISREL7and PRELIS:user's guide and reference』SPSS.
謝辞
このマニュアルを作るに当たり、東北大学文学部行動科学研究室の神林氏より、プログラムの意味について細かい点まで教えていただいた。記して深く感謝します。ただし、文章はすべて村瀬が書いたものであり、このマニュアルやプログラム例についての文責は、すべて村瀬にあります。



SPSSリズレルのプログラムの例
SPSSのデータ定義文の後に、以下のようなプログラムを書いて実行すれば、
図3で示したようなモデルの分析ができるはずです。
ミスを見つけた方は、村瀬のメールアドレスまでどんどんご連絡下さい。
/*** 以下が、リズレルのプログラム ***/
/*** 変数FSCOREからCITYAまでが調査データに実在する観測変数 ***/
/*** 変数FSCOREは父親の社会的地位 EDUは本人学歴(教育年数)***/
/*** 変数GENは現職職業威信スコア INCは本人年収 ***/
/*** 変数ZAISANは保有財産数 ***/
/*** 変数MOTIIEは居住形態 NENREIは本人年齢 ***/
/*** 変数KIBOは従業先規模 CITYAは居住地の都市度 ***/
PRELIS
/variables= FSCORE
EDU GEN INC ZAISAN
q01 q02 q03
q04 q05 q06 q07
q08 q09 q10
MOTIIE NENREI KIBO CITYA
/matrix=out(*)
/type=polychor
.
LISREL / "political awareness in SENDAI 1997"
/da ni=19 no=889 ma=pm
/la /father/gakureki/isin/syunyu/zaisan
/keniaru/zibunno/meue
/houritu/yono/fukuzatu/omakase
/seiziman/fusin/sogai
/kyojuu/nenrei/juugyou/tosi
/mo ny=15 ne=6 nx=4 fi ly=fu be=fu ga=fu ps=di
/fr ly(4,3) ly(5,3) ly(7,4) ly(8,4) ly(10,5)
ly(11,5) ly(12,5) ly(14,6) ly(15,6)
/fr be(2,1) be(2,4) be(3,1) be(3,2) be(4,1) be(5,1)
be(5,2) be(5,3) be(5,4)
be(6,1) be(6,2) be(6,3) be(6,4)
/va 1 ly(1,1) ly(2,2) ly(3,3) ly(6,4) ly(9,5) ly(13,6)
/fi te 1 te 2
/le /homenv/educ/status/econenv/author/polawr
/ou se tv ss ad=off
.
★★★ リズレルのプログラムの説明 ★★★
0.共分散構造分析の基本
共分散構造分析で用いる変数は、
1)観測変数(実際に存在する変数)
2)潜在変数(因子) の大きく2種類に分かれます。
共分散構造分析のモデルも、大きく2つに分かれます。
1)測定方程式モデル 観測変数(実際に存在する変数)で潜在変数(因子)を作る。
因子分析の部分。
2)構造方程式モデル 潜在変数(因子)の間の因果関係のモデル。
潜在変数を用いたパス解析。
構造方程式モデルに、さらに、外生変数(これも実際に存在する変数)を加えること
もある。つまり、いくつかの潜在変数と外生変数でパス解析を行う場合もある。
この文例では、一般的な因果モデルを外部から規定する要因として、4つの外生
変数(居住形態、年齢、従業先規模、都市度。プログラム例中の LISREL /laライン
の最後の4つです)をモデルに投入している。
なお、この文例では、誤差間相関はなしとしている。
1.PRELISコマンドについて
SPSSのデータのうち、LISRELで用いる変数を取り出す。
/variables以降の文で出ているのが、SPSSのデータ名である。
例えば、調査データに50個の変数があるが、分析に用いるのはそのうち19個
だけ、という場合、PRELISで19個取り出す。
/matrix=out(*)
/type=polychor と書くと多聞相関のデータ行列を出力する。
/type=covariance と書くと共分散のデータ行列を出力する。
多分相関だと、5段階尺度のような、厳密には連続変数とは言えないような、
順位尺度による相関のゆがみを補正した相関になる。社会調査データでは、
これを用いた方が良い場合もある。
しかし、多聞相関に最尤推定法を使うと、尤度が大きく歪んでしまうので、
WLS推定法を使うべきかもしれない。PRELISでは、変数の種類を指定しないとデ
フォルトの連続変数扱いになってしまうので、4段階尺度以下の場合なら、変
数に(OR)の指定をしたほうがよいらしい。5点尺度以上なら、むしろ、(CO)の
ままにしておいたほうがいいというのが通説らしいが、まだ勉強中で、この辺
は詳しくは不明です。詳しくはリズレルのマニュアルを参照してください。
2.LISRELコマンドについて
PRELISコマンドで取り出したデータを用いて、実際に分析を行う。
最初の行はタイトル。
★/daの行(データ・ライン)の指定について
ni 用いる変数の数 投入変数がprelisで指定した19個という意味
no 分析に用いるデータの人数が889人という意味。
面倒だが、PRELISの実行時に表示されるものを書く。
ma=pm PRELISで作成したpolychoric行列のデータを用いるという意味
pm多分相関 cm共分散 km相関
★/laの行の指定について PRELISに書いてある19個の変数にラベルを付けている。
★mo モデルの指定
ny 観測変数は15個 ne潜在変数6個 nx外生変数4個
nyとnxを足すと19個である
fi 外生変数を入れるときに入れる命令(外生変数を入れないときは書かなくて良い)
ly ラムダワイの行列(因子から観測変数へ行くパス)
be β行列(内生潜在変数間のパス)
ga ガンマ行列(外生変数から内生変数へのパス)
ps 内生変数の誤差間相関 ぷさい
fu行列の型の指定 −非対称行列、という意味
たいていの場合fuと書いておけばよい
di行列の型の指定 −対角行列
★fr ly ラムダワイ(測定モデル)のフリーパラメータについて
ly(観測変数の番号,潜在変数の番号)
ly(4,3)は、ラベル行4番目のsyunyuによって潜在変数3番を測定、の意味
このプログラム例では、潜在変数3番は、観測変数4,5とva行の観測変数3で測定
されていることになる。
★fr be 潜在変数間の因果関係の指定
(2,1) 1から2へのパス le行(後述)でいうとhomenvからeducのパス
★va 固定母数 1にする ly(1,1) (観測変数の番号,潜在変数の番号)
このプログラム例では、潜在変数1番と2番は、固定母数の観測変数のみで測定して
いることになる。観測変数1つで潜在変数を測定しているモデルになる。
複数の観測変数で潜在変数を作る場合、ふつう、観測変数のどれか一つを固定母数1
とする。
★fi te 1 潜在変数1は誤差を0にする、という意味
★le 潜在変数(イータ)にラベルをつける
★ou アウトプット 何を出力するかの指定
se標準誤差、tvt値 ss標準化解 ad反復推定の回数をデフォルトより多くさせる。
ou all だとすべて出力される。
外生変数(モデルの中で矢印を受けてない変数)について
ガンマについてはどの変数を用いるか指定していないので、/fr lyや/vaで指定して
いない変数がすべて外生変数になる。この文例では、19個の投入変数のうち15個
しか指定していないので、残り4つは外生変数として用いられる。
この文例だと、すべての外生変数から内生変数(因子)へのパスが存在する。
外生変数からのパスを削りたい場合以下の通り。
/fi ga(1,4)という行を挿入すると、外生変数4から内生変数1へのパスが削られる。
外生変数4とは、この文例では、19番目の投入変数tosiのこと。
( ,)内の原則は、カンマの前半の数字が結果(受け取る変数)、後半が原因
より詳しい説明は、参考文献にあげたリズレルの英文マニュアルを見てください。
付録 図2のモデルについてのプログラム
PRELIS
/variables=FSCORE EDU GEN INC ZAISAN
q01 q02 q03
q04 q05 q06
MOTIIE NENREI KIBO CITYA
/matrix=out(*)
/type=polychor
.
LISREL /"murase's sample model"
/da ni=15 no=919 ma=pm
/la /father/gakureki/isin/syunyu/zaisan
/keniaru/zibunno/meue
/houritu/yono/fukuzatu
/kyojuu/nenrei/juugyou/tosi
/mo ny=11 ne=5 nx=4 fi ly=fu be=fu ga=fu ps=di
/fr ly(4,3) ly(5,3) ly(7,4) ly(8,4) ly(10,5)
ly(11,5)
be(2,1) be(2,4) be(3,1) be(3,2) be(4,1)
be(5,1) be(5,2) be(5,3) be(5,3) be(5,4)
/fi ga(1,1) ga(1,3) ga(1,4) ga(2,1) ga(2,3)
ga(4,1) ga(4,3) ga(4,4)
/va 1 ly(1,1) ly(2,2) ly(3,3) ly(6,4) ly(9,5)
/fi te 1 te 2
/le /father/educ/status/econenv/polawr
/ou se tv ss ad=off
.
おまけ SPSSでのパス解析
SPSSで通常のパス解析を行うには、以下のような重回帰分析のプログラムを
シンタックスウィンドウに書いて、実行すればよい。私の周辺には、共分散構造分
析のように、わざわざ因子得点を使って分かりにくい変数で分析するよりも、通常
のパス解析の方がよほどよい、と言う人間がたくさんいる。
パス解析とは、通常の重回帰分析の繰り返しである。ただし、有意でないパスは
削除して、繰り返し分析を行い、最終的なモデルにたどりつくとよい。
以下のプログラムは、複数の重回帰式を分析することになる。
/MISSING LISTWISE の行によって、欠損値がある人のデータはすべて削り、
各重回帰式の分析対象の人数をすべて同じにしている。LISTWISEのかわりにMEANSUB
と書くと、欠損値を平均値で置き換える。
★なお、以前のSPSSは、複数の/DEPENDENT 行を、1つのREGRESSIONシンタックス
の中に書く(つまり、複数のモデルを一度に実行する)ことができたが、現在はでき
ないようだ。複数のモデルを書くと、どのモデルも、すべて欠損値を削除して同じ人数
になるというのがメリットだが、人数が減ってしまう。
REGRESSION
/MISSING LISTWISE
/DESCRIPTIVES MEAN STDDEV CORR SIG N
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT q10
/METHOD=ENTER age edu q5 q8 q9 .
REGRESSION
/MISSING LISTWISE
/DESCRIPTIVES MEAN STDDEV CORR SIG N
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT q8
/METHOD=ENTER age edu q5.
REGRESSION
/MISSING LISTWISE
/DESCRIPTIVES MEAN STDDEV CORR SIG N
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT q9
/METHOD=ENTER age edu q5 .
村瀬の目次に戻る
あなたは2009年11月17日以来 回目のアクセスです。
回目のアクセスです。
All Rights Reserved, Copyright(c), MURASE,Yoichi
ご意見やご質問はお気軽にどうぞ E-mail : murase (at) rikkyo.ac.jp
 ★参考 ダミー変数(二値変数)の作り方
構造方程式モデルでは、矢印が刺さっていない変数(以下の図1や図2で左端にある変数)ならば、
ダミー変数(0,1型の変数)を使ってもよい。
以下のように、何らかの新変数(名前は何でもよい。この場合はSELFEMPL)を作り、まず、全員を0にする。
その上で、IF文のかっこ内に条件を書き、条件に当てはまる人のみを1にすればよい。
以下を参考に、かっこ内には適切に条件を書く。これは2022年仙台市調査の例。問41が1,6,7の人のみ、
新変数の値を1にしてる。
COMPUTE SELFEMPL=0.
IF (Q41=1 ) SELFEMPL=1.
IF (Q41=6 OR Q41=7) SELFEMPL=1.
最初の行で、新変数SELFEMPLの中身を、全員ゼロにしている。
この3行を実行すると、新変数SELFEMPLは、自営業なら1、そうでないものは0となる。
★例 従業上の地位(Occupational Status)が正規、非正規、自営、無職の4カテゴリーの場合
→ 正規以外の3つのダミー変数を入れる。つまり、正規が基準カテゴリーとなる。
AMOSでは、→が刺さっている変数を二値変数にはできない。以下の図1や図2などで、左端にある最初の基本属性に、
自営業ダミー変数などがあるのは、問題はない。
★参考 ダミー変数(二値変数)の作り方
構造方程式モデルでは、矢印が刺さっていない変数(以下の図1や図2で左端にある変数)ならば、
ダミー変数(0,1型の変数)を使ってもよい。
以下のように、何らかの新変数(名前は何でもよい。この場合はSELFEMPL)を作り、まず、全員を0にする。
その上で、IF文のかっこ内に条件を書き、条件に当てはまる人のみを1にすればよい。
以下を参考に、かっこ内には適切に条件を書く。これは2022年仙台市調査の例。問41が1,6,7の人のみ、
新変数の値を1にしてる。
COMPUTE SELFEMPL=0.
IF (Q41=1 ) SELFEMPL=1.
IF (Q41=6 OR Q41=7) SELFEMPL=1.
最初の行で、新変数SELFEMPLの中身を、全員ゼロにしている。
この3行を実行すると、新変数SELFEMPLは、自営業なら1、そうでないものは0となる。
★例 従業上の地位(Occupational Status)が正規、非正規、自営、無職の4カテゴリーの場合
→ 正規以外の3つのダミー変数を入れる。つまり、正規が基準カテゴリーとなる。
AMOSでは、→が刺さっている変数を二値変数にはできない。以下の図1や図2などで、左端にある最初の基本属性に、
自営業ダミー変数などがあるのは、問題はない。
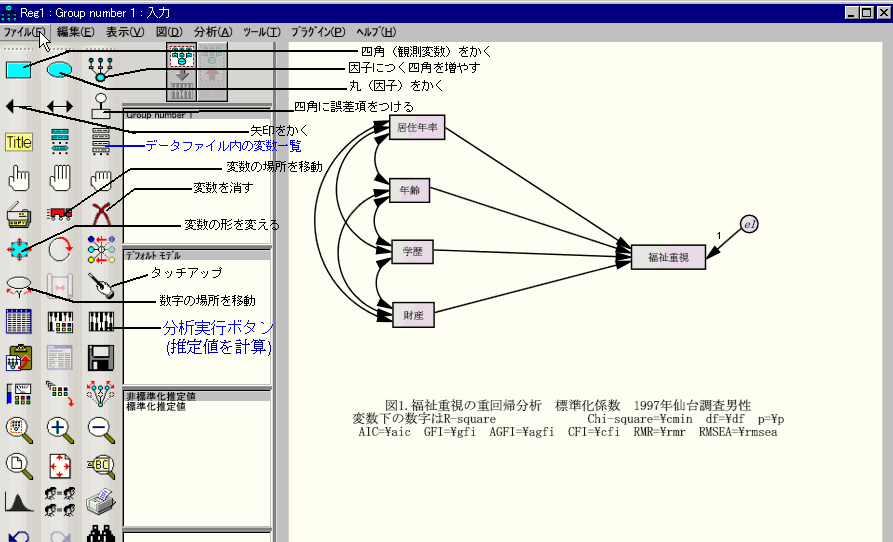 ・実在する変数は四角、因子や誤差項は楕円や丸にする。
四角や楕円のボタンを押して描く。四角の中にSPSSデータの中に実在する変数名を正確に書く。
・実在する変数は四角、因子や誤差項は楕円や丸にする。
四角や楕円のボタンを押して描く。四角の中にSPSSデータの中に実在する変数名を正確に書く。
 5)推定値を計算ボタン(鍵盤のようなボタン)を押すと分析が実行される(あるいはctrl+F9)。
以下の図を参照。変数名が間違っていると動かないので、直すこと。エラーが出たら、以下
の3.を読み、問題点は直す。
6)図の左にある赤い↑キーを押し、結果を図に表示する。その下にある
「標準化推定値」と書いてあるところをクリックすると標準化された係数が表示される。
図では、結果の数字を移動したり、R二乗を太字にしたりして、結果を見やすくする。
サンプルモデルのようにするとよい。なお、以下の図は因子を使わないパス解析の見本。
5)推定値を計算ボタン(鍵盤のようなボタン)を押すと分析が実行される(あるいはctrl+F9)。
以下の図を参照。変数名が間違っていると動かないので、直すこと。エラーが出たら、以下
の3.を読み、問題点は直す。
6)図の左にある赤い↑キーを押し、結果を図に表示する。その下にある
「標準化推定値」と書いてあるところをクリックすると標準化された係数が表示される。
図では、結果の数字を移動したり、R二乗を太字にしたりして、結果を見やすくする。
サンプルモデルのようにするとよい。なお、以下の図は因子を使わないパス解析の見本。
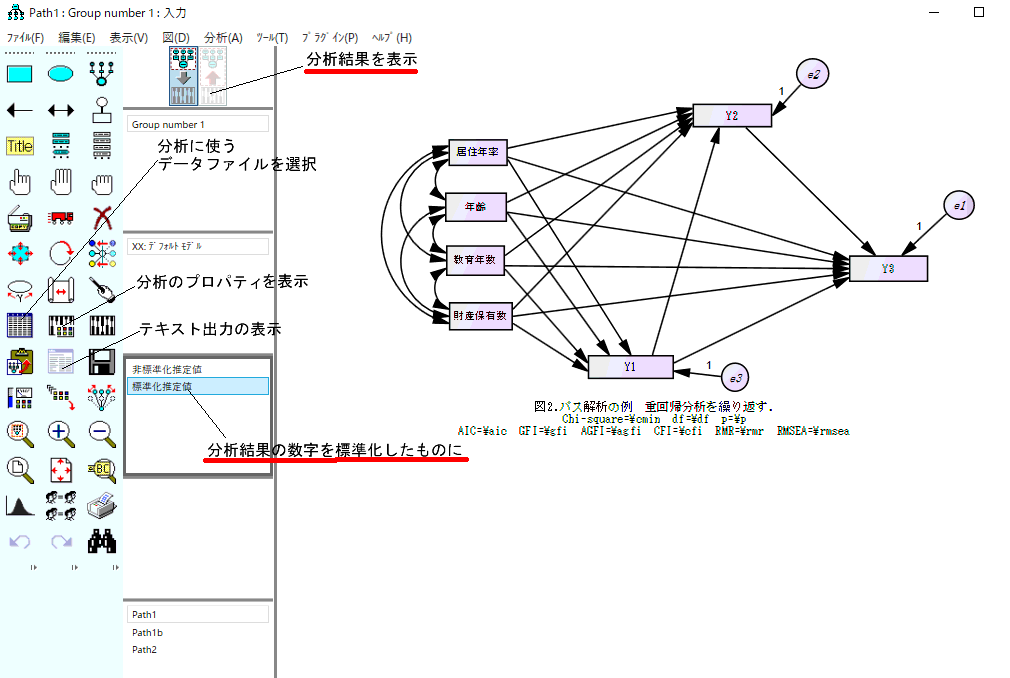 7)「表示」をクリックしてテキスト出力を読み、有意でない矢印は何か確認する。
7)「表示」をクリックしてテキスト出力を読み、有意でない矢印は何か確認する。