1)分析したい変数(質問項目)を選ぶ。その後、
「セル」ボタンを押し、列%などを選ぶ(まずは、度数のチェックははずし、列%のみを選ぶと分かりやすい表になる)
「統計」ボタンを押し、カイ二乗や相関係数やファイ係数を選ぶ。変数が3カテゴリー以上の時は、クラマーのV(値に量的意味がない場合、カテゴリー変数、質的変数)、タウBかタウC(量的変数)を選ぶとよい。3×3など正方形の表の時はタウBを使う。3×4表などではタウCを使う。
SPSSによるクロス集計
★立教SPIRIT 授業支援システムブラックボードと、立教時間も活用します。
練習用データファイルについて ★ここをクリック★ (学内のみ)
立教大学RUDA データアーカイブ(調査データファイルの検索と入手)
東大SSJデータアーカイブ(調査データファイルの検索と入手)
◆学内イントラネットへのアクセス ◆ホームディレクトリ(Hドライブ)を家から見るには
◆表とグラフ形式の基本
第三者がみて分かりやすい表とは何か、よく考えることが大切。
◆クロス表とグラフ形式
見本エクセルファイル
★SPSSシンタックスの基本 まずこれを読むこと。
おまけ やや高度な分析について
国会図書館 雑誌記事索引(雑誌は限られているが無料開放 雑誌目次内容を検索)
目的
・仕事をするための総合的能力を身につける データ分析の基礎、情報検索など その他、基礎的なPC操作やグラフ作成法、分析ソフトSPSSの基礎を習得 自分で問を設定し、建設的な批判的精神を持って考えることが重要 ・社会について分析する考え方を習得 - 根拠のない非科学的な社会評論でなく とくに良いデータとは何か理解することと、因果関係の考え方を重視 最後に、データ分析してグラフを作成し、各自の研究成果発表を行う。途中でディベートも行う。 批判的精神を身につけることが大切。何が正しいかは自分で判断する。事典や教科書、他人の発言が正しいとは限らない。主な内容
・政策と社会構造 ・テキスト講読 ・情報検索実習 ・パワーポイントなどPCの基礎実習 ・エクセルでのグラフ作成実習 ・SPSSの基礎 パソコンについては基礎からやるので、初心者でも問題ありません。 シラバス記載のテキストは必ず購入すること。
情報検索やPCでのグラフ作成実習の他、最後には各自の分析結果の発表を行なう。 1.社会とはなにか,社会学研究とは何か 2.時事問題をもとに討論 3.格差と社会階層,貧困,社会の変化 4.組織と人間 5.教育と社会的不平等 6.データ分析実習1, SPSSの基礎 7.データ分析実習2, SPSSによるデータ分析 8.選択的交際と社会統合 9.頭の中の日本社会 ―社会の認知 10.どうして「社会は変えられない」のか 11.日本社会の勤勉性のゆくえ 12.データ分析実習3, 具体的な社会調査データを分析 13.各自の分析結果を検討 14.分析結果の発表会
SPSS出力を、自分の手で数字で打ち直し、表にすると、数字の打ち間違いが起きることが多いので、出力の数字そのものをコピーして、表やグラフにすると良いでしょう。
数字をマウスで囲んでCTRL+Cでコピー準備状態、エクセル画面などに移ってからCTRL+Vではりつけです。このキー操作(コピー&ペースト)を覚えると良い。
・「ファイルの種類」をクリックし、保存形式をエクセルとする。
・ファイル名の脇の「参照」ボタンを押し、保存場所をHドライブかドキュメントなどにする。
・全てのオブジェクトを選択し、OKボタンを押す。
政府統計 e-stat
国勢調査
社会意識に関する世論調査
内閣府 集計表のエクセルファイル 各年度最後の「集計表」をクリックしCSVファイルを保存
社会生活基本調査
総務省統計局 集計表のエクセルファイル
家計・暮らしの調査報告書
日本生活協同組合連合会 集計表のエクセルファイルが過去のものはあった
就業構造基本調査結果
地域別一覧表のエクセルファイル
日本の将来推計人口
社会調査協会 リンク集
一橋大学経済研究所 附属社会科学統計情報研究センター ミクロデータの利用について
◆調査結果に関する論文など
第1章 本研究の目的 1.1.問題の所在 1.2.研究目的 1.3.先行研究 1.4.仮説 第2章 方法 調査法やデータや変数の説明など 第3章 分析結果 3.1. 3.2. など ★1.1.で研究の意義や重要性を簡潔に書き、1.2.で目的を明確に書く。目的がない文章とならないよう に。目的は、○○を解明する、というように、何をやりたいのか読者に分かるよう、明確に書くこと。 2.方法 のところには、データの出典や年度、母集団や回収率、主な変数の説明などを書いてください。 各自の作ったグラフなどは、3 分析結果 のところで、3.1. 3.2.などとして掲載すると良いでしょう。 結論部は、結果の要約ではなく、自分の主張したいことを書いてください。自分の主張と、その根拠は、 明確に分けてかくこと。 発表でも論文でも、大きな4つの構成を忘れずに! ★なお、他人の文章をコピーして自分のレポートに使ってはいけない。一部引用の際は、以下の引用法の注意をよく読むこと。
スタートボタンを押してSPSSを起動すると、まず3つ(設定によってはシンタックス以外の2つ)の画面が出てきます。分析すると、出力画面に表などが出てきます。必要に応じて保存しましょう。エクセル形式などで保存することもできます
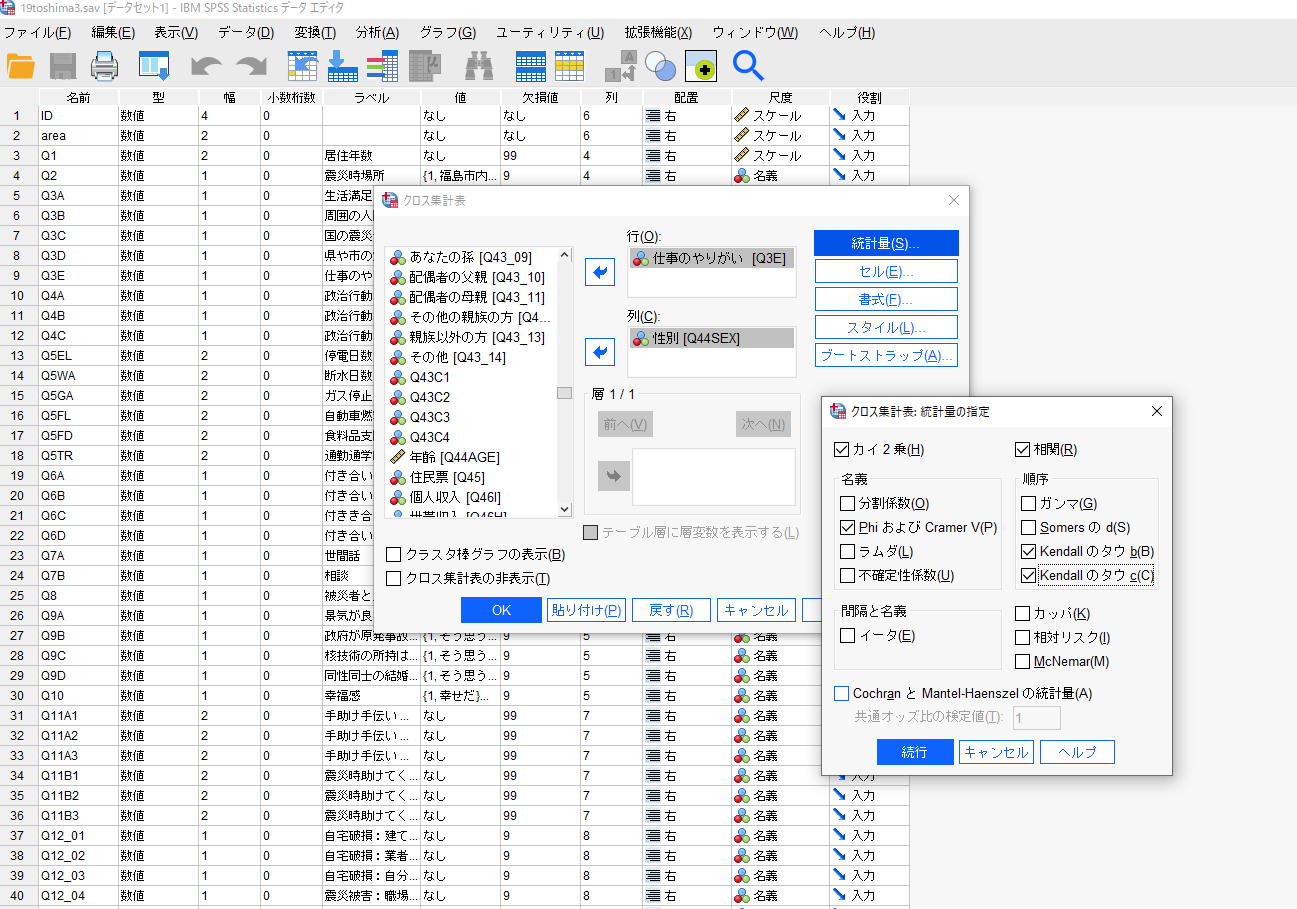
データを読み込んだ後、画面上「分析」をクリックし、記述統計→クロス集計をクリック。
1)分析したい変数(質問項目)を選ぶ。その後、
「セル」ボタンを押し、列%などを選ぶ(まずは、度数のチェックははずし、列%のみを選ぶと分かりやすい表になる)
「統計」ボタンを押し、カイ二乗や相関係数やファイ係数を選ぶ。変数が3カテゴリー以上の時は、クラマーのV(値に量的意味がない場合、カテゴリー変数、質的変数)、タウBかタウC(量的変数)を選ぶとよい。3×3など正方形の表の時はタウBを使う。3×4表などではタウCを使う。
SPSSによるクロス集計
2)OKボタンを押すと表が出る。
なお「貼り付け」ボタンを押すと、シンタックスの見本が出る。
関連係数は、有意水準が0.05未満なら、統計的に有意と考えて良い。
★クロス集計表の形式は、別途資料参照。表中の数字は%のみで実数は書かないようにすれば見やすい。両方を書くととても見にくいので注意。縦に合計して100%になるようにする。『社会調査演習 第二版』のエラボレイション(X,Y,tの3変数を使う)の表をまねすれば良い。p.84の表形式を参考に。
★3重クロス集計のシンタックスを書くときは、一番最後にtにあたる変数を書くと良い。シンタックスの中で、変数を書く順番にご注意。
表内の各変数の位置は、出力画面で、表をダブルクリックしてアクティブにした状態で、画面上の「ピポット」をクリックして入れ替えを選べば、移動できる。
相関係数や重回帰分析をやる場合は、変数の値は細かい方が良い。しかしクロス集計は、2~5カテゴリーに変数を合併してから行った方が良い。あまり細かくすると人数の少ないセルができるので。
シンタックスは、まず初めにデータの場所とデータけた(カラム)指定文などのデータ定義文を書きます。その後、欠損値処理命令文や、データの加工文、分析命令文を書きます。
まずデータファイルを開き(あるいはデータ定義文を実行した後)、SPSSのシンタックスウィンドウで、以下のようなデータ加工や分析命令のシンタックスを自分で書いて実行する。
★★その他説明(学内のみ)
/***** 例1 単純集計の例 *****/
/***** 変数名を正確に書くこと *****/
/***** ピリオドは最後に1つだけつけること *****/
FRE VAR= Q5 Q6A.
/***** 例2 2重クロス集計 縦%を出す例 ***/
/***** 変数名を正確に書くこと ***/
/***** ピリオドは最後に1つだけつけること ***/
/***** CEL行はCOUが実数、COLが縦%、rowが横% ***/
CRO
/TAB = Q15C BY Q46SEX
/STA = CHI PHI COR BTAU CTAU
/cel = COL .
/***** シンタックスによる変数の処理について *****/
/***** 例3 カテゴリー合併の例 *****/
/***** 4段階回答を2段階にしている *****/
/***** 行末のピリオドを忘れるとエラーがでるので注意*****/
COMPUTE N3 = Q3 .
RECODE N3 (1,2=1)(3,4=2) .
MISSING VALUES N3 (9) .
/***** 上記の1行目は、新変数名(新しい質問項目)として*****/
/***** N3を設定し、その中身をQ3と同じにしている。N3は *****/
/***** 好きな名前でよい。 *****/
/***** 2行目はリコード文でのカテゴリー合併 *****/
/***** 3行目は欠損値処理 *****/
★これを実行するとN3ができるが、何もおきない。このあとに、N3を使ったクロス集計など分析をするとデータの最後に変数N3が作られる。
★変数名や、RECODEを RECORD など間違えると、エラーが出るので、シンタックスを修正する。
自分で書いたシンタックスを保存しておくこと。
★大文字と小文字はこだわらなくてよい。空白は見やすいように入れる。
ただし文中に全角空白があるとエラーになるので注意。空白があってもなくても、ピリオドまでが1文として実行される。
/***** 例4 カテゴリー合併 *****/
/***** はじめに新変数としてEDUCT4を設定している *****/
/***** 新変数名は何でも好きな名前で良い *****/
/***** 1~9までの9段階の変数を4段階に変更している例 *****/
/***** 旧制の教育制度については原・海野(2004)p.204参照***/
COMPUTE EDUCT4 =Q43.
RECODE EDUCT4 (1,2,3=1)(4=2)(5=3)(6=4)(7,9=9).
MISSING VALUES EDUCT4 (9).
VALUE LABELS EDUCT4 1 '高卒以下' 2 '専門学校'
3 '短大高専' 4 '大卒以上' 9 'わからない' .
/***** 例5 変数AGE をもとに、新変数としてNENDAIを設定し、 *****/
/***** 15~98までの年齢を、2から6までの5カテゴリーに合併 *****/
COMPUTE NENDAI =AGE.
RECODE NENDAI(15 THRU 29 =2)(30 THRU 39 =3)(40 THRU 49 =4)
(50 THRU 59 =5)(60 THRU 98 =6) .
/***** 例6 学歴を教育年数に変換 *****/
COMPUTE EDU=Q16.
RECODE EDU(1=6)(2=9)(3=12)(4=13)(5=14)(6=16)(7,8,9=99).
MISSING VALUES EDU (99).
/***** 例7 ダミー変数作成 0,1の変数を作る *****/
/***** この例では自営なら1、そうでないなら0 *****/
/***** IF文は()内に条件を書き、条件に当てはまる人のみ*****/
/***** 値を変える *****/
COMPUTE JIEI =0.
IF (Q33=6) JIEI =1.
IF (Q33=7) JIEI =1.
/***** 例8 データの分割 *****/
/***** 国を表す変数countryによりデータファイルを分割する *****/
/***** 分割後に分析すると国ごとに結果が出る *****/
SORT CASES BY country.
SPLIT FILE SEPARATE BY country.
/***** 例9 3重クロス集計の例 *****/
CRO
/TABLES=Q2A BY Q10 BY Q46SEX
/CEL = COL .
/***** 例10 カテゴリー合併 年齢三段階の新変数作成 ***/
COMPUTE NEN3 =Q46AGE.
RECODE NEN3 (10 THRU 39 =3)(40 THRU 59 =5)(60 THRU 97 =7).
VALUE LABELS NEN3 3 'under39' 5 'under59' 7 'over60' .
/*** 新旧変数のクロス集計で分布を確認 ***/
CRO /TAB = NEN3 BY Q46AGE.
/***** 例11 問2Bの変数の回答を逆転。N2Bが逆転した新変数 *****/
Compute N2B=5-Q2B.
/***** 例12 問7Aと問7Bの回答内容を足して、合計得点の新変数NEW7を作成 *****/
Compute NEW7=Q7A+Q7B.
/***** 例13 既婚ダミー変数作成 ***/
COMPUTE MADMY =0.
IF (Q28 =1) MADMY =1.
MISSING VALUES MADMY (9).
/***** 例14 非正規雇用ダミー変数作成 ***/
/***** 臨時雇用、アルバイト、派遣、嘱託、契約社員などはすべて非正規とする ***/
compute HISEIKI = 0.
if (Q33 =3) HISEIKI = 1.
if (Q33 =4) HISEIKI = 1.
if (Q33 =5) HISEIKI = 1.
if (Q33 =8) HISEIKI = 1.
/***** 例15 本人の従業上地位作成 ***/
Compute jobstats= q33.
RECODE jobstats (1=1)(2=3) (3,4,5=4)(6,7=5)(else=9).
IF ((q34>5) and (q36 = 4)) jobstats=2.
IF ((q34>5) and (q36 = 5)) jobstats=2.
IF ((q34<6) and (q33 = 1)) jobstats=5.
VALUE LABELS jobstats 1 '経営者' 2 '管理職' 3 '常時雇用' 4 '非正規雇用' 5 '自営・家族従業者' 9 '無職' .
まず新変数jobstatsはQ33と同じ内容とする。その後RECODE文でjobstatsの内容を
変更している。
次にIF文で、q34従業先規模が大きい場合、q36で4課長相当の人を管理職にする。
次にIF文で、q34従業先規模が大きい場合、q36で5部長相当の人を管理職にする。
次にIF文で、q34従業先規模が小さい場合、q33で1経営者・役員を自営業にする。
/*** 例 クロス集計シンタックス例 ***/
/*** 新変数と元の変数を集計して内容を確認***/
CRO /TAB= jobstats by Q33 .
/*** 例16 平均値折れ線グラフ ***/
ONEWAY
Q6A Q6B edu BY nendai
/PLOT MEANS
/STA DES.
★BYの後は、説明変数になるものを1つだけ書く。前は、複数の変数を書いても良い。
onewayは、一元配置分散分析をせよ、という命令文(変数nendaiごとの平均値の例)
PLOT文で平均値の折れ線グラフを出す。
STA文で基本統計量を出す。年代ごとの平均値など出すと便利。
例11のように逆転した新変数の平均値を出した方が分かりやすいことがある。
例12のように合計得点の平均値を出してもよい。
年代など各カテゴリーの人数は度数分布を見て事前に確認しておく。
/***** 例17 欠損値を除いてデータ人数を減らす *****/
/***** AMOS使用前に人数を減らしたデータを作り保存しておくこと***/
SELECT IF age < 99.
SELECT IF edu ne 99.
SELECT IF Q1 ne 99.
SELECT IF livrate < 2.
SELECT IF Q2A <9.
SELECT IF Q2B <9.
SELECT IF PROPERTY <99.
SELECT IF FAMILYNO <9.
SELECT IF TYONAI <9.
SELECT IF YAKUNIN <9.
/*** その他のシンタックス見本 変数名は調査によって異なる ***/
/*** 全角空白や全角のかっこやピリオドがあるとエラーになる ***/
/*** 行末にピリオドがない、ピリオドをつけすぎなどもエラーになるので注意 ***/
/***** 個人収入と世帯収入を万円に直す *****/
compute incomei = q48i.
recode incomei (1=0) (2=50) (3=110) (4=200) (5=300)
(6=400) (7=500) (8=600) (9=700) (10=800) (11=925) (12=1100)
(13=1300) (14=1500) (16=1700).
compute incomeh = q48h.
recode incomeh (1=0) (2=50) (3=110) (4=200) (5=300)
(6=400) (7=500) (8=600) (9=700) (10=800) (11=925) (12=1100)
(13=1300) (14=1500) (16=1700).
/***** 財産保有項目の合計値の新変数property *****/
compute property = Q32_01+Q32_02+Q32_03+Q32_04+Q32_05+Q32_06+Q32_07+Q32_08+Q32_09+Q32_10+Q32_11+Q32_12+Q32_13+Q32_14.
/***** データチェック 値が0という人のIDを出す ***/
compute ch1 =0.
if (q34 =0) ch1 =ID.
/***** 性別ダミー *****/
select if Q46SEX < 9.
compute sexdmy =0.
if (Q46SEX=1) sexdmy =1.
IF (Q46SEX=9) sexdmy =9.
missing values sexdmy(9).
/***** 福島市2015年調査 *****/
/***** ガス停止無回答を0日に *****/
/***** 直前の3問で無回答の人はガス停止日数を無回答でなく値を0にする*****/
COMPUTE Q5ch1 =0.
IF ((Q5EL ne 99) and (Q5WA ne 99)) Q5ch1 =1.
COMPUTE Q5ch2 =0.
IF ((Q5ch1=1) and (Q5FL ne 99)) Q5ch2 =1.
COMPUTE Q5GA2 =Q5GA.
IF ((Q5GA=99) and (Q5ch2=1)) Q5GA2 =0.
より詳しくは、 「応用調査実習」ホームページを見てください。
・データのあるドライブ名、フォルダ名はあっているか。CドライブをHと書いた等
・変数名はあっているか。Q6AをQ6と書いた等
・単純なスペルのミス。例えば、RECODEと書くべきところを RECORDと書いた等
・最後にピリオドをつけるのを忘れた。あるいは途中で余計なピリオドをつけた。
・シンタックスの中に全角スペースがあると、エラーが出て止まるので注意!
Hドライブの場合は、H:と書く。\ マークで区切ってフォルダ位置を書く。
RECORDS=2は1人分が2行のデータの場合。この後に桁指定文を書きピリオドを書く。その後に、リコード文や、各種の分析命令文を書けばよい。
この後に桁指定文はいらない。この後にリコード文や分析命令文などを書く。
その他、
・シンタックス内では、大文字と小文字は区別されない。
・シンタックス内では、半角space、改行、tabは区別されない。ピリオドがあるまで1文として処理される。
ワード画面で挿入 → オブジェクトを選ぶ
挿入するのはエクセルワークシート
ワード画面上の「罫線」をクリックすると表になってしまうので、線だけを引きたいときは以下のようにする。
・ワードの画面上「挿入」をクリック
・図形 → 線を選択し、マウスで線を引く書いた線や図を微調整したいときは、書いた線や図を右クリックして「図形の書式設定」を選ぶ。線の太さや矢印種類などを変更できる。
二乗などの、小さい2を書きたいときは、2を書いてからマウスで字を選んで右クリックし「フォント」を選ぶ。「文字飾り」の中の上付ボックスをチェックする。
「社会学科 村瀬ゼミ」ホームページの説明を参照。
文献リストの形式 - 著者名と発行年(半角数字)を最初に書き、その後に、「論文名」『本や雑誌名』と発行所を書くこと。本や雑誌名は二重かっこを使う。詳しくはテキスト等の巻末引用文献リストの形式を参考に。
基本的に、ネット上の情報やネット上百科事典、ネット上データは、ガセネタも多く信憑性が低い。個人が趣味で作っただけで正確なチェックはなく、いいかげんで信用できない情報が多い。また、すぐに消えてしまう情報も多いので、研究においてはできるだけ使わないこと。必要な情報は、本として出版されているものから引用すること。本として形になっているものの方が信用度は高い。
また、ネット上にあるグラフを、そのままコピーして自分のレポートで使うことは、図やデザインの無断使用となるので著作権法違反である。自分でデータの数字を入手して、グラフを自分で作り直すこと。
ネット上の情報は、個人が趣味で作ったいいかげんな情報が多く、ミスが編集者によってチェックされることは少ない。そのため、最新のデータや、信用できるデータは、ネット上にはかなり少ないのが事実である。とくにネット上にあるフリー百科事典や掲示板などは、「ガセネタ」も多く、よく調べずに曖昧な記憶や直感で書いた情報も多いので、内容を信用してはいけない。多くの場合、最新のデータは本や統計資料となっているので、データを調べるときは、必ず図書館へ行くこと。データ検索をネットのみですませることは、絶対にしてはいけない。図書館の参考室には、各種の事典や図鑑、数十冊からなる百科事典もある。まず百科事典の索引を使いこなすと良い。
赤川学.2004.『子供が減って何が悪いか!』筑摩書房.
文春新書編集部編. 2006. 『論争 格差社会』文藝春秋.
中央公論編集部編.2001.『論争・中流崩壊』中央公論新社.
ロバート=C=クリストファー.1983.『ジャパニーズ・マインド』講談社.
土場学編.2004.『社会を“モデル”でみる ―数理社会学への招待』勁草書房.
ロナルド=ドーア. 2006. 『誰のための会社にするか』岩波新書.
原純輔.1981.「階層構造論」.安田三郎・塩原勉・富永健一・吉田民人編.『基礎社会
学4:社会構造』東洋経済新報社原純輔編.2002.『流動化と社会格差』ミネルヴァ書房.
原純輔・盛山和夫.1999.『社会階層 豊かさの中の不平等』東京大学出版会.
原純輔他編.2000.『日本の階層システム』1~6巻.東京大学出版会.
原純輔・海野道郎.2004.『社会調査演習 第2版』東京大学出版会.
橋本健二. 2018.『新・日本の階級社会 (講談社現代新書)』講談社.
橋本健二. 2018.『アンダークラス (ちくま新書) 』筑摩書房.
橋本健二. 2020.『中流崩壊』朝日新聞出版.
林信吾. 2005. 『しのびよるネオ階級社会 ―“イギリス化”する日本の格差』平凡社.
樋口美雄・財務省財務総合政策研究所.2003.『日本の所得格差と社会階層』日本評論社.
平野浩. 2007. 『変容する日本の社会と投票行動』木鐸社.
本田由紀. 2009. 『教育の職業的意義―若者、学校、社会をつなぐ』筑摩書房.
今田高俊.1989.『社会階層と政治』東京大学出版会.
稲葉陽二. 2011. 『ソーシャル・キャピタル入門 ―孤立から絆へ』中公新書.
石田浩編. 2017. 『教育とキャリア [格差の連鎖と若者]』勁草書房.
コリン=ジョイス. 2006. 『「ニッポン社会」入門―英国人記者の抱腹レ
ポート』日本放送出版協会.
蒲島郁夫.1988.『政治参加』東京大学出版会.
鹿又伸夫.2001.『機会と結果の不平等』ミネルヴァ書房.
苅谷剛彦.2001.『階層化日本と教育危機 ―不平等再生産から意欲格差社会(インセン
ティブ・ディバイド)へ』有信堂高文社.
吉川徹. 2018. 『日本の分断 ―切り離される非大卒若者(レッグス)たち』光文社.
小林淳一・木村邦博編著.1991.『考える社会学』ミネルヴァ書房.
小林淳一・木村邦博編著.1997.『数理の発想で見る社会』ナカニシヤ出版.
高坂健次・厚東洋輔編.1998.『講座社会学1 理論と方法』東京大学出版会.
三船毅. 2008. 『現代日本における政治参加意識の構造と変動』慶應義塾大学出版会.
三浦展. 2005. 『下流社会 -新たな階層集団の出現』光文社新書.
宮野勝.1986.「誤答効果と非回答バイアス:投票率を例として」.『理論と方法』
Vol.1 No.1:101-114、ハーベスト社.
村上泰亮.1984.『新中間大衆の時代』中央公論社.
村瀬洋一.2006.「階級階層をめぐる社会学」宇都宮京子編『よくわかる社会学』ミネ
ルヴァ書房.
永吉希久子. 2020. 『移民と日本社会 ―データで読み解く実態と将来像』中央公論新社.
中野雅至.2006.『格差社会の結末 -富裕層の傲慢・貧困層の怠慢』ソフトバンク新書.
直井優他編.1990.『現代日本の階層構造』第1~4巻.東京大学出版会.
大竹文雄.2005.『日本の不平等』日本経済新聞社.
大竹文雄.2010.『日本の幸福度―格差・労働・家族』日本評論社.
レイブ・マーチ著=佐藤嘉倫・大澤定順・都築一治訳.1991.『社会科学のためのモデル
入門』ハーベスト社.
佐藤俊樹.2000. 『不平等社会日本 ―さよなら総中流』中央公論新社.
佐藤嘉倫他編. 2011. 『現代の階層社会』1~3巻.東京大学出版会.
佐藤嘉倫・木村敏明. 2013. 『不平等生成メカニズムの解明 ―格差・階層・公正』ミネルヴァ書房
盛山和夫他.2005.『「社会」への知 現代社会学の理論と方法 上下巻』勁草書房.
盛山和夫.2011. 『経済成長は不可能なのか―少子化と財政難を克服する条件』中央公論新社.
盛山和夫他編. 2011.『日本の社会階層とそのメカニズム ―不平等を問い直す』白桃書房.
盛山和夫他. 2015. 『社会を数理で読み解く ―不平等とジレンマの構造』有斐閣.
数土直紀. 2010. 『日本人の階層意識』講談社.
数土直紀. 2013. 『信頼にいたらない世界 ―権威主義から公正へ』勁草書房.
数土直紀. 2015. 『社会意識からみた日本 ―階層意識の新次元』有斐閣.
数土直紀・今田高俊.2005.『数理社会学入門』勁草書房.
曽良中清司.1983.『権威主義的人間 -現代人の心にひそむファシズム』有斐閣.
橘木俊詔.1998.『日本の経済格差』岩波書店.
も格差が大きく、経済的に平等な社会とは言えないと主張している。
橘木俊詔.2006.『格差社会 何が問題なのか』岩波書店.
田辺俊介. 2011. 『外国人へのまなざしと政治意識 ―社会調査で読み解く日本のナショナリズム』勁草書房.
田辺俊介. 2019. 『日本人は右傾化したのか ―データ分析で実像を読み解く』勁草書房.
谷口尚子. 2005. 『現代日本の投票行動』慶應義塾大学出版会.
谷岡一郎.2000.『「社会調査」のウソ -リサーチ・リテラシーのすすめ』文芸春秋.谷岡一郎, 仁田道夫, 岩井紀子編. 2008. 『日本人の意識と行動 : 日本版総合的社会調査JGSSによる分析』東京大学出版会.
富永健一.1979.『日本の階層構造』東京大学出版会.
友野典男. 2006. 『行動経済学 -経済は「感情」で動いている』光文社新書.
筒井淳也. 2015. 『仕事と家族 ―日本はなぜ働きづらく、産みにくいのか』中央公論新社
筒井淳也他編. 2016. 『計量社会学入門 ―社会をデータでよむ』世界思想社.
和田英樹.2006.『「新中流」の誕生 -ポスト階層分化社会を探る』中公新書.
山口二郎.2004.『戦後政治の崩壊 -デモクラシーはどこへゆくか』岩波書店.
山口一男. 2017.『働き方の男女不平等 ―理論と実証分析』日本経済新聞出版社.
安田三郎.1971.『社会移動の研究』東京大学出版会.
安田三郎・海野道郎.1977.『改訂2版 社会統計学』丸善.
安田三郎・原純輔.1982.『社会調査ハンドブック(第3版)』有斐閣.2200円.
寄本勝美.2003.『リサイクル社会への道』岩波新書.
与謝野有紀編.2006.『社会の見方、測り方 ―計量社会学への招待』勁草書房.
和田英樹.2006.『「新中流」の誕生 -ポスト階層分化社会を探る』中公新書.
2005年SSM調査研究会.2008.『2005年SSM調査シリーズ』第1~15巻.2005年SS M調査研究会.
その他 仕事の技術に関する本
ボーンシュテット・ノーキ著=海野道郎・中村隆監訳.1990.『社会統計学 -社会調査
のためのデータ分析入門』ハーベスト社.
★社会統計学の入門書として分かりやすい。
海野道郎・原純輔.2004.『社会調査演習 改訂版』東京大学出版会.
★巻末の調査票や調査員マニュアル見本が分かりやすい。
本多勝一. 1982. 『日本語の作文技術』朝日新聞社.
岸学.2005.『SPSSによるやさしい統計学』オーム社.
野口悠紀雄. 1993. 『「超」整理法 ―情報検索と発想の新システム』中央公論社.
梅棹忠夫. 1967. 『知的生産の技術』岩波新書.